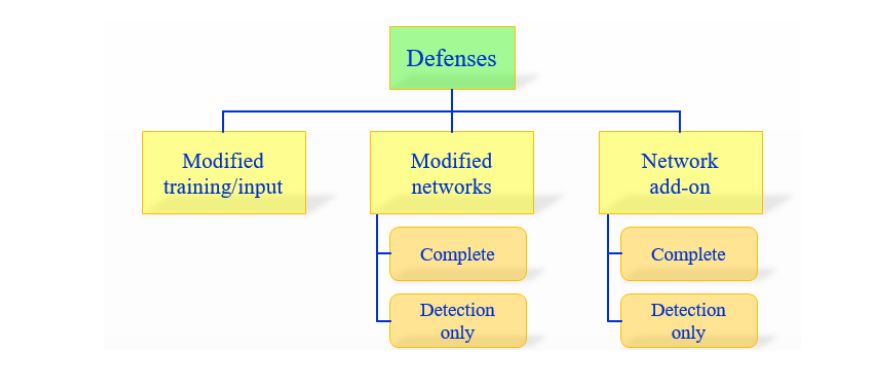
1)在学习过程中修改训练过程或者修改的输入样本。
2)修改网络,比如:添加更多层/子网络、改变损失/激活函数等。
3)当分类未见过的样本时,用外部模型作为附加网络。
第一个方法没有直接处理学习模型。
另外两个分类是更加关心神经网络本身的。
这些方法可以被进一步细分为两种类型:
(a)完全防御;(b)仅探测(detection only)。
「完全防御」方法的目标是让网络将对抗样本识别为正确的类别。
分为对抗训练 (adversarial training)、梯度掩蔽 (gradient masking)、输入转换 (input transformation) 和基于邻域分类 (region-based classification) 四种
「仅探测」方法意味着在对抗样本上发出报警以拒绝任何进一步的处理。
基于局部本征维数的检测, Feature Squeezing, MagNet
1 修改训练过程/ 输入数据
1 蛮力对抗训练
一般对抗训练, PGD对抗训练,集成对抗训练
不断输入新类型的对抗样本并执行对抗训练,从而不断提升网络的鲁棒性。为了保证有效性,该方法需要使用高强度的对抗样本,并且网络架构要有充足的表达能力。这种方法需要大量的训练数据,因而被称为蛮力对抗训练。
可以正则化网络以减少过拟合
但是可能无论添加多少对抗样本,都存在新的对抗攻击样本可以再次欺骗网络。
在训练过程中包含对抗样本的信息,从而构建一个鲁棒性更好的分类器。但是很难推断出攻击者的攻击方式,无法得知攻击者产生的对抗样本的模式、每种对抗样本的比重。
集成对抗训练防御方法将对抗训练的过程与对抗样本的产生过程分开,在对抗训练的过程中加入对抗样本是通过攻击其他模型产生的,增加了所加入对抗样本的多样性,从而提高模型抵御其他攻击方法的能力。
2 数据压缩
注意到大多数训练图像都是 JPG 格式,使用 JPG 图像压缩的方法,减少对抗扰动对准确率的影响。实验证明该方法对部分对抗攻击算法有效,但通常仅采用压缩方法是远远不够的,并且压缩图像时同时也会降低正常分类的准确率,后来提出的 PCA 压缩方法也有同样的缺点。
3 基于中央凹机制的防御
用中央凹(foveation)机制可以防御 L-BFGS 和 FGSM 生成的对抗扰动,其假设是图像分布对于转换变动是鲁棒的,而扰动不具备这种特性。但这种方法的普遍性尚未得到证明。
4 数据随机化方法
对训练图像引入随机重缩放可以减弱对抗攻击的强度,其它方法还包括随机 padding、训练过程中的图像增强等。
2 修改网络
5 深度压缩网络
简单地将去噪自编码器(Denoising Auto Encoders)堆叠到原来的网络上只会使其变得更加脆弱
因而引入了深度压缩网络(Deep Contractive Networks),其中使用了和压缩自编码器(Contractive Auto Encoders)类似的平滑度惩罚项。
使得模型的输出变化对输入敏感性降低,从而达到隐藏梯度信息的目的
6 梯度正则化/ masking
在训练的目标函数上惩罚输出对于输入的变化程度,可以在一定程度上限制小的对抗扰动,不会大幅改变最终模型的预测结果。
使用输入梯度正则化以提高对抗攻击鲁棒性,该方法和蛮力对抗训练结合有很好的效果,但计算复杂度太高。
7 Defensive distillation
利用蒸馏方法训练两个串联的 DNN 模型来提高模型预测的鲁棒性
证明其可以抵抗小幅度扰动的对抗攻击。
在训练过程中通过各种方式隐藏梯度信息,从而使得攻击很难通过梯度求解方法攻击目标训练器,但是该防御方法很容易被各种攻击技巧绕过。
并不能增加神经网络的鲁棒性,而且这种防御方法需要改变并重新训练目标分类器,增加了工程上的复杂性。
8 生物启发的防御方法
使用类似与生物大脑中非线性树突计算的高度非线性激活函数以防御对抗攻击
9 Parseval 网络
在一层中利用全局 Lipschitz 常数加控制,利用保持每一层的 Lipschitz 常数来摆脱对抗样本的干扰。
10 DeepCloak
在分类层(一般为输出层)前加一层特意为对抗样本训练的层。它背后的理论认为在最显著的层里包含着最敏感的特征。
11 混杂方法
这章包含了多个人从多种角度对深度学习模型的调整从而使模型可以抵抗对抗性攻击。
12 仅探测方法
这章介绍了 4 种网络,SafetyNet,Detector subnetwork,Exploiting convolution filter statistics 及 Additional class augmentation。
- SafetyNet 介绍了 ReLU 对对抗样本的模式与一般图片的不一样,文中介绍了一个用 SVM 实现的工作。
- Detector subnetwork 介绍了用 FGSM, BIM 和 DeepFool 方法实现的对对抗样本免疫的网络的优缺点。
- Exploiting convolution filter statistics 介绍了同 CNN 和统计学的方法做的模型在分辨对抗样本上可以有 85% 的正确率。
训练一个分类器来区分对抗样本与正常样本,与对抗训练方法不同的是:对抗训练只是改善了原有分类器的正确性,而该方法是额外增加一个分类器。
3 使用附加网络
13 防御通用扰动
利用一个单独训练的网络加在原来的模型上,从而达到不需要调整系数而且免疫对抗样本的方法。
14 基于 GAN 的防御
用 GAN 为基础的网络可以抵抗对抗攻击,而且作者提出在所有模型上用相同的办法来做都可以抵抗对抗样本。
15 仅探测方法
介绍了 Feature Squeezing、MagNet 以及混杂的办法。
- Feature Squeezing 方法用了两个模型来探查是不是对抗样本。后续的工作介绍了这个方法对 C&W 攻击也有能接受的抵抗力。
- MagNet: 作者用一个分类器对图片的流行(manifold)测量值来训练,从而分辨出图片是不是带噪声的。
- 混杂方法(Miscellaneous Methods):作者训练了一个模型,把所有输入图片当成带噪声的,先学习怎么去平滑图片,之后再进行分类。
基于邻域分类防御从待预测样本邻域范围内随机选取若干个样本,利用原模型对取样后的所有样本进行预测,再采用多数表决方式选择预测标签最多的作为待预测样本最终的标签
Challenge
基于对抗训练的防御
需要大量的对抗样本,极大地增加了训练的时间和所需资源, 使得该防御很难在实际场景的大规模数据集上使用
由于训练过程中只能加入由已知攻击产生的且有限的对抗样本,因此对抗训练防御通常只对与加入训练同类型的对抗样本有效,对其他攻击产生的对抗样本不具有泛化能力。
梯度掩蔽防御
一个简单绕过该防御的方法是,攻击者通过训练一个与防御后的模型相似的替代模型,进而通过使用替代模型的梯度来构造对抗样本,从而达到绕过防御后模型的目的。
需要改变模型结构并重新训练分类器,进一步增加了该防御方法在工程上的复杂性。
基于输入转换的防御
一般不改变任何模型网络结构和训练数据集,但是需要对待预测样本进行转换处理。理论上,输入转换方法对任何种类的 攻击样本都有一定的防御效果,但是实验表明这种防御方法在对抗样本预测上的误报率和漏报率较大。
基于邻域分类的防御
主要利用待预测样本邻域范围内其他样本的预测值。该方法有两个非常重要的参数,分别是邻域范围半径 r 和采样个数 N。 但是r 越大,分类器预测正常样本的准确率越低 ; 而 r 越小,该方法对对抗样本的防御效果就会越差。 同样地,N 越大,该方法的效率会成倍数增加 ;N 越小,防御效果也会越差。
检测防御
对正常样本的分类准确率会降低,并没有说明检测结果为“对抗样本”的解决方法。
Summary
每种防御方法都只能抵御有限的对抗样本,并且很容易被不断进化和变种的对抗样本绕过
现有防御方法都是一种被动式的防御,只能防御某一类攻击,不能够解决 0-Day 攻击等未知风险
研究人员研究了 ICLR 2018 收录的八篇关于对抗样本的论文中的防御方法鲁棒性,发现其中七种防御方法可以通过改进的攻击算法来攻破

